修改 conf\jvm.option 文件
-Xms340m
-Xmx340m
修改 conf\elasticsearch.yml 文件
http.cors.enabled: true
http.cors.allow-origin: "*"
network.host: 127.0.0.1
文件中一些重要的注释和配置选项:
http.cors.enabled: true和http.cors.allow-origin: "*":启用跨域请求(CORS)功能,并允许所有来源的请求通过。network.host: 127.0.0.1:将 Elasticsearch 绑定到本地主机上,只能在本地访问。xpack.security.enabled: true:启用 Elasticsearch 的安全功能。xpack.security.transport.ssl和xpack.security.http.ssl:指定用于加密和相互认证的 SSL 证书路径。cluster.name:为集群指定名称。node.name:为节点指定名称。path.data和path.logs:分别指定数据和日志文件的存储路径。bootstrap.memory_lock:锁定内存以提高性能。network.host和http.port:分别指定网络接口地址和 HTTP 端口号。discovery.seed_hosts和cluster.initial_master_nodes:设置集群发现和初始化节点的主节点列表。action.destructive_requires_name:是否允许使用通配符删除索引。
这些注释和配置选项都是 Elasticsearch 配置文件中常见的设置,可根据实际需求进行调整。
启动 elasticsearch.bat、使用自带的 jdk
简介
搜索引擎原理
ES 优点
-
分布式的功能
-
数据高可用,集群高可用
-
API 更简单
-
API 更高级。
-
支持的语言很多
-
支持 PB 级别的数据
-
完成搜索的功能和分析功能
基于 Lucene,隐藏了 Lucene 的复杂性,提供简单的 API
ES 的性能比 HBase 高
搜索引擎原理
反向索引又叫倒排索引,是根据文章内容中的关键字建立索引。
搜索引擎原理就是建立反向索引。
Elasticsearch 在 Lucene 的基础上进行封装,实现了分布式搜索引擎。
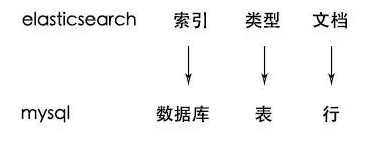
Elasticsearch 中的索引、类型和文档的概念比较重要,类似于 MySQL 中的数据库、表和行。
Elasticsearch 也是 Master-slave 架构,也实现了数据的分片和备份。
Elasticsearch 一个典型应用就是 ELK 日志分析系统。
作用
-
全文检索:
类似
select * from product where product_name like '%牙膏%'类似百度效果(电商搜索的效果)
-
结构化搜索:
类似
select * from product where product_id = '1' -
数据分析
类似
select count (*) from product
ES 的核心概念
index 索引(索引库)
index 类似于我们 Mysql 里面的一个数据库 create database user; 好比就是一个索引库
type 类型
类型是用来定义数据结构的
在每一个 index 下面,可以有一个或者多个 type,好比数据库里面的一张表。
相当于表结构的描述,描述每个字段的类型。
text类型会被分词器分词,keyword不会被分开
document:文档
文档就是最终的数据了,可以认为一个文档就是一条记录。
是 ES 里面最小的数据单元,就好比表里面的一条数据
Field 字段
类似关系型数据库中列的概念,一个 document 有一个或者多个 field 组成。
shard:分片
一台服务器,无法存储大量的数据,ES 把一个 index 里面的数据,分为多个 shard,分布式的存储在各个服务器上面。
replica:副本
一个分布式的集群,难免会有一台或者多台服务器宕机,如果我们没有副本这个概念。就会造成我们的 shard 发生故障,无法提供正常服务。
在 ES 集群中,我们一模一样的数据有多份,能正常提供查询和插入的分片我们叫做 primary shard,其余的我们就管他们叫做 replica shard(备份的分片)
当我们去查询数据的时候,我们数据是有备份的,它会同时发出命令让我们有数据的机器去查询结果,最后谁的查询结果快,我们就要谁的数据(这个不需要我们去控制,它内部就自己控制了)
总结
在默认情况下,我们创建一个库的时候,默认会帮我们创建 5 个主分片(primary shrad)和 5 个副分片(replica shard),所以说正常情况下是有 10 个分片的。
同一个节点上面,副本和主分片是一定不会在一台机器上面的,就是拥有相同数据的分片,是不会在同一个节点上面的。
所以当你有一个节点的时候,这个分片是不会把副本存在这仅有的一个节点上的,当你新加入了一台节点,ES 会自动的给你在新机器上创建一个之前分片的副本。
ES 的相关命令
PUT 类似于 SQL 中的增
DELETE 类似于 SQL 中的删
POST 类似于 SQL 中的改
GET 类似于 SQL 中的查
PUT /aura_index
用于创建一个名为 "aura_index" 的索引。具体来说,该请求会在 Elasticsearch 中创建一个新的索引,并将其设置为默认类型
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "aura_index"
}
- acknowledged:表示该操作是否被集群中的所有节点都接受和处理。
- shards_acknowledged:表示分片是否已确认该操作。如果所有分片都确认了该操作,则值为 true。如果某些分片未能确认该操作,则值为 false。
- index:表示刚刚创建的索引的名称。
GET _cat/indices
返回yellow open aura_index 87wIbbg-Q_mLLFadvLbfsw 1 1 0 0 225b 225b
当您在 Elasticsearch 环境中执行 "_cat/indices" 命令时,它将返回一个表格,其中包含有关所有索引的信息。下面是一些常见参数的含义:
- health:该索引的健康状况。可以是 green、yellow 或 red 中的任何一个。green 表示所有分片都可用,yellow 表示所有主分片可用但不是所有副本分片都可用,red 表示至少有一个主分片不可用。
- status:该索引的状态。可以是 open 或 closed 中的任何一个。open 表示该索引可写入和查询,closed 表示该索引只能查询。
- index:该索引的名称。
- uuid:该索引的唯一标识符。
- pri:该索引的主分片数量。
- rep:该索引的副本分片数量。
- docs.count:该索引中文档的数量。
- docs.deleted:该索引中已被标记为删除的文档数量。
- store.size:该索引占用的存储空间大小。
- pri.store.size:该索引主分片占用的存储空间大小。
DELETE /aura_index
删除一个 aura_index 的 index 库

需要注意的是,删除操作不可逆,一旦执行,就无法恢复删除的数据
ES 的 CURD 操作
新增
PUT /ecommerce/_doc/1
{
"id": "987654321",
"name": "华为 P50 Pro",
"description": "华为(HUAWEI)P50 Pro 4G手机 8GB+128GB 芝士金",
"category": ["电子产品", "手机"],
"price": 6988,
"brand": "华为",
"color": "芝士金",
"created_at": "2023-04-14T15:35:36.924Z"
}
响应数据
{
"_index": "ecommerce",
"_id": "1",
"_version": 3,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 2,
"_primary_term": 1
}
表示新增成功
- 根据 mapping 创建索引和类型
PUT /test
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "integer"
},
"birthday":{
"type": "date"
}
}
}
}
查询
GET /ecommerce/_doc/1
响应,当found=false时表示未找到
{
"_index": "ecommerce",
"_id": "1",
"_version": 3,
"_seq_no": 2,
"_primary_term": 1,
"found": true,
"_source": {
"id": "987654321",
"name": "华为 P50 Pro",
"description": "华为(HUAWEI)P50 Pro 4G手机 8GB+128GB 芝士金",
"category": ["电子产品", "手机"],
"price": 6988,
"brand": "华为",
"color": "芝士金",
"created_at": "2023-04-14T15:35:36.924Z"
}
}
删除
DELETE /ecommerce/_doc/1
{
"_index": "ecommerce",
"_id": "1",
"_version": 4,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 3,
"_primary_term": 1
}
更新
POST 和 PUT 都可以更新
POST的方式进行修改数据,POST是局部更新数据,别的数据不动。PUT是全局更新,修改单个字段的值一定要用 POST
POST /ecommerce/_doc/1
{
"id": "987654321",
"name": "华为 P80 Pro",
"description": "华为(HUAWEI)P50 Pro 4G手机 8GB+128GB 芝士金",
"category": [
"电子产品",
"手机"
],
"price": 6988,
"brand": "华为",
"color": "芝士金",
"created_at": "2023-04-14T15:35:36.924Z"
}
再次新增两条数据
POST /ecommerce/_doc/1
{
"id": "787654321",
"name": "小米",
"description": "小米手机 8GB+128GB 芝士��金",
"category": [
"电子产品",
"手机"
],
"price": 3000,
"brand": "小米",
"color": "芝士金",
"created_at": "2023-04-15T15:35:36.924Z"
}
POST /ecommerce/_doc/1
{
"id": "787654321",
"name": "苹果",
"description": "苹果手机 8GB+128GB 芝士金",
"category": [
"电子产品",
"手机"
],
"price": 8999,
"brand": "苹果",
"color": "芝士金",
"created_at": "2023-04-15T15:35:36.924Z"
}
查询所有的数据
match_all 匹配所有
GET ecommerce/_search
{
"query": {
"match_all": {}
}
}
响应
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 3,
"relation": "eq"
},
"max_score": 1,
"hits": [
{
"_index": "ecommerce",
"_id": "1",
"_score": 1,
"_source": {
"id": "787654321",
"name": "苹果",
"description": "苹果手机 8GB+128GB 芝士金",
"category": ["电子产品", "手机"],
"price": 8999,
"brand": "苹果",
"color": "芝士金",
"created_at": "2023-04-16T15:35:36.924Z"
}
},
{
"_index": "ecommerce",
"_id": "3",
"_score": 1,
"_source": {
"id": "987654321",
"name": "华为 P80 Pro",
"description": "华为(HUAWEI)P50 Pro 4G手机 8GB+128GB 芝士金",
"category": ["电子产品", "手机"],
"price": 10000,
"brand": "华为",
"color": "芝士金",
"created_at": "2023-04-14T15:35:36.924Z"
}
},
{
"_index": "ecommerce",
"_id": "2",
"_score": 1,
"_source": {
"id": "787654321",
"name": "小米",
"description": "小米手机 8GB+128GB 芝士金",
"category": ["电子产品", "手机"],
"price": 3000,
"brand": "小米",
"color": "芝士金",
"created_at": "2023-04-15T15:35:36.924Z"
}
}
]
}
}
解释:
took: 查询执行所需的时间(以毫秒为单位)。timed_out: 如果查询超时,则为 true;如果未超时,则为 false。_shards: 有关查询分片的信息。"total" 属性指示查询涉及到的分片总数,"successful" 属性表示成功查询的分片数,"skipped" 表示跳过的分片数,而 "failed" 属性表示失败的分片数。hits: 包含有关查询结果的信息。"total" 属性指示匹配文档的总数,"max_score" 指示最高得分,"hits" 则包含所有匹配文档的详细信息。- 对于每个匹配文档,"_index" 属性指示该文档所在的索引,"_id" 属性则是该文档的 ID,"_score" 属性则是该文档与查询的匹配得分。"_source" 属性包含该文档的实际内容,其中包括 ID、名称、描述、类别、价格、品牌、颜色和创建日期等属性。
- 如果查询未返回任何结果,则 "total" 属性的 "value" 值将为 0,且 "relation" 值将为 "eq"。
DSL 语言
DSL(Domain Specific Language)是 Elasticsearch 中用于查询和筛选文档的语言。它基于 JSON 语法,并包含一组特定的查询语句和过滤器,可以执行以下操作:
- 匹配查询:比较指定字段与指定值,查找匹配项。
- 多字�段查询:在多个字段中搜索指定值。
- 范围查询:检索指定范围内的数据(例如,价格在某个区间内)。
- 前缀查询:在一个或多个字段中匹配以指定前缀开头的所有条目。
- 通配符查询:使用 * 或 ? 等通配符匹配一定模式的数据。
- 正则表达式查询:使用正则表达式匹配数据。
- 模糊查询:在指定字段中查找与给定单词相似的文本。
- 短语查询:查找包含完整短语的文本。
- 过滤器查询:仅返回满足特定条件的文档。
- 分页查询:将结果分为多个页面进行查询。
- 排序查询:按指定属性对结果进行排序。
- 聚合查询:对数据进行统计、分组或其他聚合操作。